Memory Guide
Memory enables Claude to retain context across sessions and conversations. It exists in two forms: automatic synthesis in claude.ai, and filesystem-based CLAUDE.md in Claude Code.
Overview
Memory in Claude Code provides persistent context that carries across multiple sessions and conversations. Unlike temporary context windows, memory files allow you to:
- Share project standards across your team
- Store personal development preferences
- Maintain directory-specific rules and configurations
- Import external documentation
- Version control memory as part of your project
The memory system operates at multiple levels, from global personal preferences down to specific subdirectories, allowing for fine-grained control over what Claude remembers and how it applies that knowledge.
Memory Commands Quick Reference
| Command | Purpose | Usage | When to Use |
|---|---|---|---|
/init | Initialize project memory | /init | Starting new project, first-time CLAUDE.md setup |
/memory | Edit memory files in editor | /memory | Extensive updates, reorganization, reviewing content |
# prefix | Quick single-line memory add | # Your rule here | Adding quick rules during conversation |
# new rule into memory | Explicit memory addition | # new rule into memory<br/>Your detailed rule | Adding complex multi-line rules |
# remember this | Natural language memory | # remember this<br/>Your instruction | Conversational memory updates |
@path/to/file | Import external content | @README.md or @docs/api.md | Referencing existing documentation in CLAUDE.md |
Quick Start: Initializing Memory
The /init Command
The /init command is the fastest way to set up project memory in Claude Code. It initializes a CLAUDE.md file with foundational project documentation.
Usage:
/initWhat it does:
- Creates a new CLAUDE.md file in your project (typically at
./CLAUDE.mdor./.claude/CLAUDE.md) - Establishes project conventions and guidelines
- Sets up the foundation for context persistence across sessions
- Provides a template structure for documenting your project standards
Enhanced interactive mode: Set CLAUDE_CODE_NEW_INIT=true to enable a multi-phase interactive flow that walks you through project setup step by step:
CLAUDE_CODE_NEW_INIT=true claude
/initWhen to use /init:
- Starting a new project with Claude Code
- Establishing team coding standards and conventions
- Creating documentation about your codebase structure
- Setting up memory hierarchy for collaborative development
Example workflow:
# In your project directory
/init
# Claude creates CLAUDE.md with structure like:
# Project Configuration
## Project Overview
- Name: Your Project
- Tech Stack: [Your technologies]
- Team Size: [Number of developers]
## Development Standards
- Code style preferences
- Testing requirements
- Git workflow conventionsQuick Memory Updates with #
You can quickly add information to memory during any conversation by starting your message with #:
Syntax:
# Your memory rule or instruction hereExamples:
# Always use TypeScript strict mode in this project
# Prefer async/await over promise chains
# Run npm test before every commit
# Use kebab-case for file namesHow it works:
- Start your message with
#followed by your rule - Claude recognizes this as a memory update request
- Claude asks which memory file to update (project or personal)
- The rule is added to the appropriate CLAUDE.md file
- Future sessions automatically load this context
Alternative patterns:
# new rule into memory
Always validate user input with Zod schemas
# remember this
Use semantic versioning for all releases
# add to memory
Database migrations must be reversibleThe /memory Command
The /memory command provides direct access to edit your CLAUDE.md memory files within Claude Code sessions. It opens your memory files in your system editor for comprehensive editing.
Usage:
/memoryWhat it does:
- Opens your memory files in your system’s default editor
- Allows you to make extensive additions, modifications, and reorganizations
- Provides direct access to all memory files in the hierarchy
- Enables you to manage persistent context across sessions
When to use /memory:
- Reviewing existing memory content
- Making extensive updates to project standards
- Reorganizing memory structure
- Adding detailed documentation or guidelines
- Maintaining and updating memory as your project evolves
Comparison: /memory vs /init
| Aspect | /memory | /init |
|---|---|---|
| Purpose | Edit existing memory files | Initialize new CLAUDE.md |
| When to use | Update/modify project context | Begin new projects |
| Action | Opens editor for changes | Generates starter template |
| Workflow | Ongoing maintenance | One-time setup |
Example workflow:
# Open memory for editing
/memory
# Claude presents options:
# 1. Managed Policy Memory
# 2. Project Memory (./CLAUDE.md)
# 3. User Memory (~/.claude/CLAUDE.md)
# 4. Local Project Memory
# Choose option 2 (Project Memory)
# Your default editor opens with ./CLAUDE.md content
# Make changes, save, and close editor
# Claude automatically reloads the updated memoryUsing Memory Imports:
CLAUDE.md files support the @path/to/file syntax to include external content:
# Project Documentation
See @README.md for project overview
See @package.json for available npm commands
See @docs/architecture.md for system design
# Import from home directory using absolute path
@~/.claude/my-project-instructions.mdImport features:
- Both relative and absolute paths are supported (e.g.,
@docs/api.mdor@~/.claude/my-project-instructions.md) - Recursive imports are supported with a maximum depth of 5
- First-time imports from external locations trigger an approval dialog for security
- Import directives are not evaluated inside markdown code spans or code blocks (so documenting them in examples is safe)
- Helps avoid duplication by referencing existing documentation
- Automatically includes referenced content in Claude’s context
Memory Architecture
Memory in Claude Code follows a hierarchical system where different scopes serve different purposes:
Memory Hierarchy in Claude Code
Claude Code uses a multi-tier hierarchical memory system. Memory files are automatically loaded when Claude Code launches, with higher-level files taking precedence.
Complete Memory Hierarchy (in order of precedence):
-
Managed Policy - Organization-wide instructions
- macOS:
/Library/Application Support/ClaudeCode/CLAUDE.md - Linux/WSL:
/etc/claude-code/CLAUDE.md - Windows:
C:\Program Files\ClaudeCode\CLAUDE.md
- macOS:
-
Managed Drop-ins - Alphabetically merged policy files (v2.1.83+)
managed-settings.d/directory alongside the managed policy CLAUDE.md- Files are merged in alphabetical order for modular policy management
-
Project Memory - Team-shared context (version controlled)
./.claude/CLAUDE.mdor./CLAUDE.md(in repository root)
-
Project Rules - Modular, topic-specific project instructions
./.claude/rules/*.md
-
User Memory - Personal preferences (all projects)
~/.claude/CLAUDE.md
-
User-Level Rules - Personal rules (all projects)
~/.claude/rules/*.md
-
Local Project Memory - Personal project-specific preferences
./CLAUDE.local.md
Note:
CLAUDE.local.mdis not mentioned in the official documentation as of March 2026. It may still work as a legacy feature. For new projects, consider using~/.claude/CLAUDE.md(user-level) or.claude/rules/(project-level, path-scoped) instead.
- Auto Memory - Claude’s automatic notes and learnings
~/.claude/projects/<project>/memory/
Memory Discovery Behavior:
Claude searches for memory files in this order, with earlier locations taking precedence:
Excluding CLAUDE.md Files with claudeMdExcludes
In large monorepos, some CLAUDE.md files may be irrelevant to your current work. The claudeMdExcludes setting lets you skip specific CLAUDE.md files so they are not loaded into context:
// In ~/.claude/settings.json or .claude/settings.json
{
"claudeMdExcludes": [
"packages/legacy-app/CLAUDE.md",
"vendors/**/CLAUDE.md"
]
}Patterns are matched against paths relative to the project root. This is particularly useful for:
- Monorepos with many sub-projects, where only some are relevant
- Repositories that contain vendored or third-party CLAUDE.md files
- Reducing noise in Claude’s context window by excluding stale or unrelated instructions
Settings File Hierarchy
Claude Code settings (including autoMemoryDirectory, claudeMdExcludes, and other configuration) are resolved from a five-level hierarchy, with higher levels taking precedence:
| Level | Location | Scope |
|---|---|---|
| 1 (Highest) | Managed policy (system-level) | Organization-wide enforcement |
| 2 | managed-settings.d/ (v2.1.83+) | Modular policy drop-ins, merged alphabetically |
| 3 | ~/.claude/settings.json | User preferences |
| 4 | .claude/settings.json | Project-level (committed to git) |
| 5 (Lowest) | .claude/settings.local.json | Local overrides (git-ignored) |
Platform-specific configuration (v2.1.51+):
Settings can also be configured via:
- macOS: Property list (plist) files
- Windows: Windows Registry
These platform-native mechanisms are read alongside JSON settings files and follow the same precedence rules.
Modular Rules System
Create organized, path-specific rules using the .claude/rules/ directory structure. Rules can be defined at both the project level and user level:
your-project/
├── .claude/
│ ├── CLAUDE.md
│ └── rules/
│ ├── code-style.md
│ ├── testing.md
│ ├── security.md
│ └── api/ # Subdirectories supported
│ ├── conventions.md
│ └── validation.md
~/.claude/
├── CLAUDE.md
└── rules/ # User-level rules (all projects)
├── personal-style.md
└── preferred-patterns.mdRules are discovered recursively within the rules/ directory, including any subdirectories. User-level rules at ~/.claude/rules/ are loaded before project-level rules, allowing personal defaults that projects can override.
Path-Specific Rules with YAML Frontmatter
Define rules that apply only to specific file paths:
---
paths: src/api/**/*.ts
---
# API Development Rules
- All API endpoints must include input validation
- Use Zod for schema validation
- Document all parameters and response types
- Include error handling for all operationsGlob Pattern Examples:
**/*.ts- All TypeScript filessrc/**/*- All files under src/src/**/*.{ts,tsx}- Multiple extensions{src,lib}/**/*.ts, tests/**/*.test.ts- Multiple patterns
Subdirectories and Symlinks
Rules in .claude/rules/ support two organizational features:
- Subdirectories: Rules are discovered recursively, so you can organize them into topic-based folders (e.g.,
rules/api/,rules/testing/,rules/security/) - Symlinks: Symlinks are supported for sharing rules across multiple projects. For example, you can symlink a shared rule file from a central location into each project’s
.claude/rules/directory
Memory Locations Table
| Location | Scope | Priority | Shared | Access | Best For |
|---|---|---|---|---|---|
/Library/Application Support/ClaudeCode/CLAUDE.md (macOS) | Managed Policy | 1 (Highest) | Organization | System | Company-wide policies |
/etc/claude-code/CLAUDE.md (Linux/WSL) | Managed Policy | 1 (Highest) | Organization | System | Organization standards |
C:\Program Files\ClaudeCode\CLAUDE.md (Windows) | Managed Policy | 1 (Highest) | Organization | System | Corporate guidelines |
managed-settings.d/*.md (alongside policy) | Managed Drop-ins | 1.5 | Organization | System | Modular policy files (v2.1.83+) |
./CLAUDE.md or ./.claude/CLAUDE.md | Project Memory | 2 | Team | Git | Team standards, shared architecture |
./.claude/rules/*.md | Project Rules | 3 | Team | Git | Path-specific, modular rules |
~/.claude/CLAUDE.md | User Memory | 4 | Individual | Filesystem | Personal preferences (all projects) |
~/.claude/rules/*.md | User Rules | 5 | Individual | Filesystem | Personal rules (all projects) |
./CLAUDE.local.md | Project Local | 6 | Individual | Git (ignored) | Personal project-specific preferences |
~/.claude/projects/<project>/memory/ | Auto Memory | 7 (Lowest) | Individual | Filesystem | Claude’s automatic notes and learnings |
Memory Update Lifecycle
Here’s how memory updates flow through your Claude Code sessions:
Auto Memory
Auto memory is a persistent directory where Claude automatically records learnings, patterns, and insights as it works with your project. Unlike CLAUDE.md files which you write and maintain manually, auto memory is written by Claude itself during sessions.
How Auto Memory Works
- Location:
~/.claude/projects/<project>/memory/ - Entrypoint:
MEMORY.mdserves as the main file in the auto memory directory - Topic files: Optional additional files for specific subjects (e.g.,
debugging.md,api-conventions.md) - Loading behavior: The first 200 lines of
MEMORY.mdare loaded into the system prompt at session start. Topic files are loaded on demand, not at startup. - Read/write: Claude reads and writes memory files during sessions as it discovers patterns and project-specific knowledge
Auto Memory Architecture
Auto Memory Directory Structure
~/.claude/projects/<project>/memory/
├── MEMORY.md # Entrypoint (first 200 lines loaded at startup)
├── debugging.md # Topic file (loaded on demand)
├── api-conventions.md # Topic file (loaded on demand)
└── testing-patterns.md # Topic file (loaded on demand)Version Requirement
Auto memory requires Claude Code v2.1.59 or later. If you are on an older version, upgrade first:
npm install -g @anthropic-ai/claude-code@latestCustom Auto Memory Directory
By default, auto memory is stored in ~/.claude/projects/<project>/memory/. You can change this location using the autoMemoryDirectory setting (available since v2.1.74):
// In ~/.claude/settings.json or .claude/settings.local.json (user/local settings only)
{
"autoMemoryDirectory": "/path/to/custom/memory/directory"
}Note:
autoMemoryDirectorycan only be set in user-level (~/.claude/settings.json) or local settings (.claude/settings.local.json), not in project or managed policy settings.
This is useful when you want to:
- Store auto memory in a shared or synced location
- Separate auto memory from the default Claude configuration directory
- Use a project-specific path outside the default hierarchy
Worktree and Repository Sharing
All worktrees and subdirectories within the same git repository share a single auto memory directory. This means switching between worktrees or working in different subdirectories of the same repo will read and write to the same memory files.
Subagent Memory
Subagents (spawned via tools like Task or parallel execution) can have their own memory context. Use the memory frontmatter field in the subagent definition to specify which memory scopes to load:
memory: user # Load user-level memory only
memory: project # Load project-level memory only
memory: local # Load local memory onlyThis allows subagents to operate with focused context rather than inheriting the full memory hierarchy.
Controlling Auto Memory
Auto memory can be controlled via the CLAUDE_CODE_DISABLE_AUTO_MEMORY environment variable:
| Value | Behavior |
|---|---|
0 | Force auto memory on |
1 | Force auto memory off |
| (unset) | Default behavior (auto memory enabled) |
# Disable auto memory for a session
CLAUDE_CODE_DISABLE_AUTO_MEMORY=1 claude
# Force auto memory on explicitly
CLAUDE_CODE_DISABLE_AUTO_MEMORY=0 claudeAdditional Directories with --add-dir
The --add-dir flag allows Claude Code to load CLAUDE.md files from additional directories beyond the current working directory. This is useful for monorepos or multi-project setups where context from other directories is relevant.
To enable this feature, set the environment variable:
CLAUDE_CODE_ADDITIONAL_DIRECTORIES_CLAUDE_MD=1Then launch Claude Code with the flag:
claude --add-dir /path/to/other/projectClaude will load CLAUDE.md from the specified additional directory alongside the memory files from your current working directory.
Practical Examples
Example 1: Project Memory Structure
File: ./CLAUDE.md
# Project Configuration
## Project Overview
- **Name**: E-commerce Platform
- **Tech Stack**: Node.js, PostgreSQL, React 18, Docker
- **Team Size**: 5 developers
- **Deadline**: Q4 2025
## Architecture
@docs/architecture.md
@docs/api-standards.md
@docs/database-schema.md
## Development Standards
### Code Style
- Use Prettier for formatting
- Use ESLint with airbnb config
- Maximum line length: 100 characters
- Use 2-space indentation
### Naming Conventions
- **Files**: kebab-case (user-controller.js)
- **Classes**: PascalCase (UserService)
- **Functions/Variables**: camelCase (getUserById)
- **Constants**: UPPER_SNAKE_CASE (API_BASE_URL)
- **Database Tables**: snake_case (user_accounts)
### Git Workflow
- Branch names: `feature/description` or `fix/description`
- Commit messages: Follow conventional commits
- PR required before merge
- All CI/CD checks must pass
- Minimum 1 approval required
### Testing Requirements
- Minimum 80% code coverage
- All critical paths must have tests
- Use Jest for unit tests
- Use Cypress for E2E tests
- Test filenames: `*.test.ts` or `*.spec.ts`
### API Standards
- RESTful endpoints only
- JSON request/response
- Use HTTP status codes correctly
- Version API endpoints: `/api/v1/`
- Document all endpoints with examples
### Database
- Use migrations for schema changes
- Never hardcode credentials
- Use connection pooling
- Enable query logging in development
- Regular backups required
### Deployment
- Docker-based deployment
- Kubernetes orchestration
- Blue-green deployment strategy
- Automatic rollback on failure
- Database migrations run before deploy
## Common Commands
| Command | Purpose |
|---------|---------|
| `npm run dev` | Start development server |
| `npm test` | Run test suite |
| `npm run lint` | Check code style |
| `npm run build` | Build for production |
| `npm run migrate` | Run database migrations |
## Team Contacts
- Tech Lead: Sarah Chen (@sarah.chen)
- Product Manager: Mike Johnson (@mike.j)
- DevOps: Alex Kim (@alex.k)
## Known Issues & Workarounds
- PostgreSQL connection pooling limited to 20 during peak hours
- Workaround: Implement query queuing
- Safari 14 compatibility issues with async generators
- Workaround: Use Babel transpiler
## Related Projects
- Analytics Dashboard: `/projects/analytics`
- Mobile App: `/projects/mobile`
- Admin Panel: `/projects/admin`Example 2: Directory-Specific Memory
File: ./src/api/CLAUDE.md
# API Module Standards
This file overrides root CLAUDE.md for everything in /src/api/
## API-Specific Standards
### Request Validation
- Use Zod for schema validation
- Always validate input
- Return 400 with validation errors
- Include field-level error details
### Authentication
- All endpoints require JWT token
- Token in Authorization header
- Token expires after 24 hours
- Implement refresh token mechanism
### Response Format
All responses must follow this structure:
```json
{
"success": true,
"data": { /* actual data */ },
"timestamp": "2025-11-06T10:30:00Z",
"version": "1.0"
}Error responses:
{
"success": false,
"error": {
"code": "VALIDATION_ERROR",
"message": "User message",
"details": { /* field errors */ }
},
"timestamp": "2025-11-06T10:30:00Z"
}Pagination
- Use cursor-based pagination (not offset)
- Include
hasMoreboolean - Limit max page size to 100
- Default page size: 20
Rate Limiting
- 1000 requests per hour for authenticated users
- 100 requests per hour for public endpoints
- Return 429 when exceeded
- Include retry-after header
Caching
- Use Redis for session caching
- Cache duration: 5 minutes default
- Invalidate on write operations
- Tag cache keys with resource type
### Example 3: Personal Memory
**File:** `~/.claude/CLAUDE.md`
```markdown
# My Development Preferences
## About Me
- **Experience Level**: 8 years full-stack development
- **Preferred Languages**: TypeScript, Python
- **Communication Style**: Direct, with examples
- **Learning Style**: Visual diagrams with code
## Code Preferences
### Error Handling
I prefer explicit error handling with try-catch blocks and meaningful error messages.
Avoid generic errors. Always log errors for debugging.
### Comments
Use comments for WHY, not WHAT. Code should be self-documenting.
Comments should explain business logic or non-obvious decisions.
### Testing
I prefer TDD (test-driven development).
Write tests first, then implementation.
Focus on behavior, not implementation details.
### Architecture
I prefer modular, loosely-coupled design.
Use dependency injection for testability.
Separate concerns (Controllers, Services, Repositories).
## Debugging Preferences
- Use console.log with prefix: `[DEBUG]`
- Include context: function name, relevant variables
- Use stack traces when available
- Always include timestamps in logs
## Communication
- Explain complex concepts with diagrams
- Show concrete examples before explaining theory
- Include before/after code snippets
- Summarize key points at the end
## Project Organization
I organize my projects as:
project/
├── src/
│ ├── api/
│ ├── services/
│ ├── models/
│ └── utils/
├── tests/
├── docs/
└── docker/
## Tooling
- **IDE**: VS Code with vim keybindings
- **Terminal**: Zsh with Oh-My-Zsh
- **Format**: Prettier (100 char line length)
- **Linter**: ESLint with airbnb config
- **Test Framework**: Jest with React Testing LibraryMy Test Ask Claude to save a new rule
 Claude has not save the rule because I did not have any
Claude has not save the rule because I did not have any Claude.md file anywhere. Then asked Claude to confirm the location.
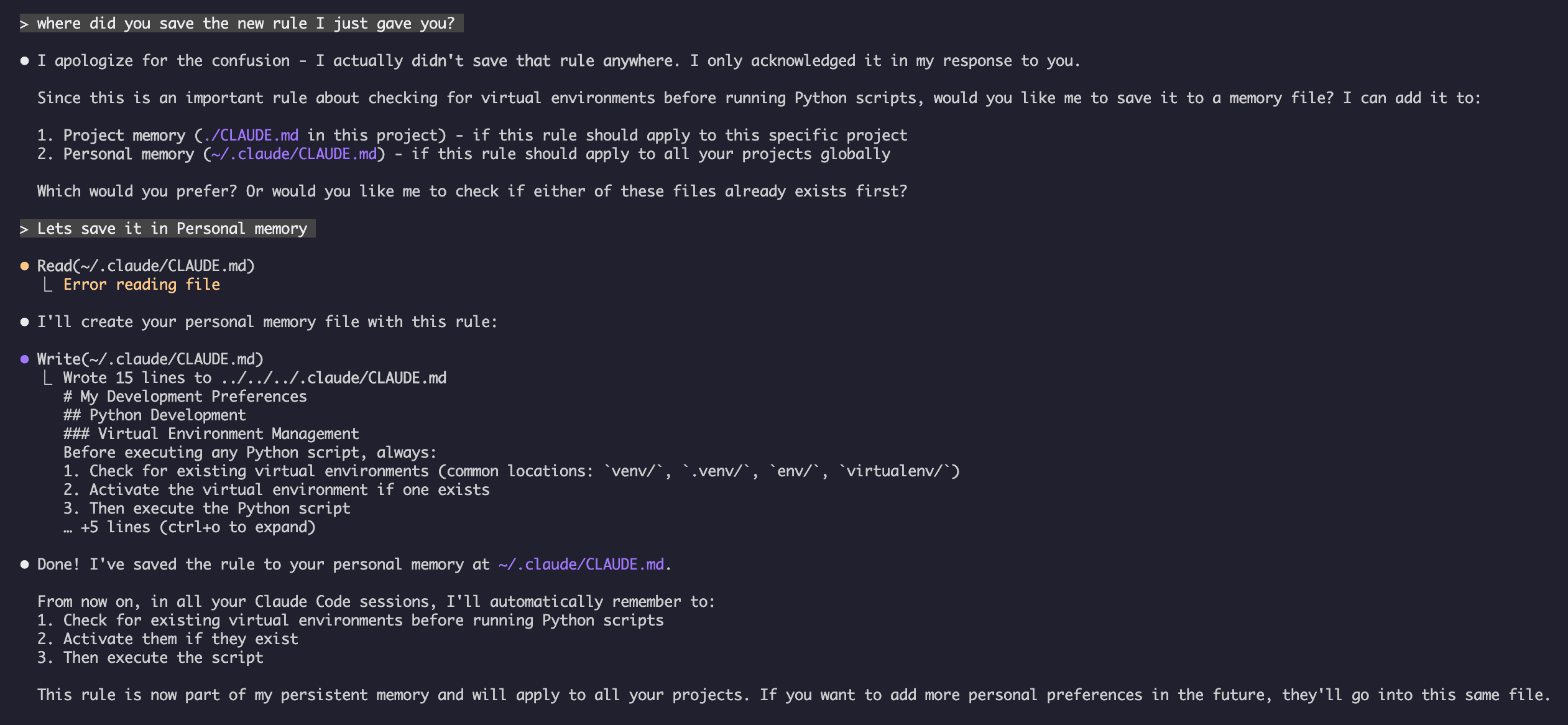
Example 4: Memory Update During Session
You can add new rules to memory during an active Claude Code session. There are two ways to do this:
Method 1: Direct Request
User: Remember that I prefer using React hooks instead of class components
for all new components.
Claude: I'm adding that to your memory. Which memory file should this go in?
1. Project memory (./CLAUDE.md)
2. Personal memory (~/.claude/CLAUDE.md)
User: Project memory
Claude: ✅ Memory saved!
Added to ./CLAUDE.md:
---
### Component Development
- Use functional components with React Hooks
- Prefer hooks over class components
- Custom hooks for reusable logic
- Use useCallback for event handlers
- Use useMemo for expensive computationsMethod 2: Using ”# new rule into memory” Pattern
You can also use the explicit pattern ”# new rule into memory” to trigger memory updates:
User: # new rule into memory
Always validate user input with Zod schemas before processing.
Claude: I'm saving this rule to memory. Which memory file should I use?
1. Project memory (./CLAUDE.md)
2. Personal memory (~/.claude/CLAUDE.md)
User: Project memory
Claude: ✅ Memory saved!
Added to ./CLAUDE.md:
---
### Input Validation
- Always validate user input with Zod schemas before processing
- Define schemas at the top of each API handler file
- Return 400 status with validation errorsTips for Adding Memory
- Be specific and actionable in your rules
- Group related rules together under a section header
- Update existing sections instead of duplicating content
- Choose the appropriate memory scope (project vs. personal)
Memory Features Comparison
| Feature | Claude Web/Desktop | Claude Code (CLAUDE.md) |
|---|---|---|
| Auto-synthesis | ✅ Every 24h | ❌ Manual |
| Cross-project | ✅ Shared | ❌ Project-specific |
| Team access | ✅ Shared projects | ✅ Git-tracked |
| Searchable | ✅ Built-in | ✅ Through /memory |
| Editable | ✅ In-chat | ✅ Direct file edit |
| Import/Export | ✅ Yes | ✅ Copy/paste |
| Persistent | ✅ 24h+ | ✅ Indefinite |
Memory in Claude Web/Desktop
Memory Synthesis Timeline
Example Memory Summary:
## Claude's Memory of User
### Professional Background
- Senior full-stack developer with 8 years experience
- Focus on TypeScript/Node.js backends and React frontends
- Active open source contributor
- Interested in AI and machine learning
### Project Context
- Currently building e-commerce platform
- Tech stack: Node.js, PostgreSQL, React 18, Docker
- Working with team of 5 developers
- Using CI/CD and blue-green deployments
### Communication Preferences
- Prefers direct, concise explanations
- Likes visual diagrams and examples
- Appreciates code snippets
- Explains business logic in comments
### Current Goals
- Improve API performance
- Increase test coverage to 90%
- Implement caching strategy
- Document architectureBest Practices
Do’s - What To Include
-
Be specific and detailed: Use clear, detailed instructions rather than vague guidance
- ✅ Good: “Use 2-space indentation for all JavaScript files”
- ❌ Avoid: “Follow best practices”
-
Keep organized: Structure memory files with clear markdown sections and headings
-
Use appropriate hierarchy levels:
- Managed policy: Company-wide policies, security standards, compliance requirements
- Project memory: Team standards, architecture, coding conventions (commit to git)
- User memory: Personal preferences, communication style, tooling choices
- Directory memory: Module-specific rules and overrides
-
Leverage imports: Use
@path/to/filesyntax to reference existing documentation- Supports up to 5 levels of recursive nesting
- Avoids duplication across memory files
- Example:
See @README.md for project overview
-
Document frequent commands: Include commands you use repeatedly to save time
-
Version control project memory: Commit project-level CLAUDE.md files to git for team benefit
-
Review periodically: Update memory regularly as projects evolve and requirements change
-
Provide concrete examples: Include code snippets and specific scenarios
Don’ts - What To Avoid
-
Don’t store secrets: Never include API keys, passwords, tokens, or credentials
-
Don’t include sensitive data: No PII, private information, or proprietary secrets
-
Don’t duplicate content: Use imports (
@path) to reference existing documentation instead -
Don’t be vague: Avoid generic statements like “follow best practices” or “write good code”
-
Don’t make it too long: Keep individual memory files focused and under 500 lines
-
Don’t over-organize: Use hierarchy strategically; don’t create excessive subdirectory overrides
-
Don’t forget to update: Stale memory can cause confusion and outdated practices
-
Don’t exceed nesting limits: Memory imports support up to 5 levels of nesting
Memory Management Tips
Choose the right memory level:
| Use Case | Memory Level | Rationale |
|---|---|---|
| Company security policy | Managed Policy | Applies to all projects organization-wide |
| Team code style guide | Project | Shared with team via git |
| Your preferred editor shortcuts | User | Personal preference, not shared |
| API module standards | Directory | Specific to that module only |
Quick update workflow:
- For single rules: Use
#prefix in conversation - For multiple changes: Use
/memoryto open editor - For initial setup: Use
/initto create template
Import best practices:
# Good: Reference existing docs
@README.md
@docs/architecture.md
@package.json
# Avoid: Copying content that exists elsewhere
# Instead of copying README content into CLAUDE.md, just import itInstallation Instructions
Setup Project Memory
Method 1: Using /init Command (Recommended)
The fastest way to set up project memory:
-
Navigate to your project directory:
cd /path/to/your/project -
Run the init command in Claude Code:
/init -
Claude will create and populate CLAUDE.md with a template structure
-
Customize the generated file to match your project needs
-
Commit to git:
git add CLAUDE.md git commit -m "Initialize project memory with /init"
Method 2: Manual Creation
If you prefer manual setup:
-
Create a CLAUDE.md in your project root:
cd /path/to/your/project touch CLAUDE.md -
Add project standards:
cat > CLAUDE.md << 'EOF' # Project Configuration ## Project Overview - **Name**: Your Project Name - **Tech Stack**: List your technologies - **Team Size**: Number of developers ## Development Standards - Your coding standards - Naming conventions - Testing requirements EOF -
Commit to git:
git add CLAUDE.md git commit -m "Add project memory configuration"
Method 3: Quick Updates with #
Once CLAUDE.md exists, add rules quickly during conversations:
# Use semantic versioning for all releases
# Always run tests before committing
# Prefer composition over inheritanceClaude will prompt you to choose which memory file to update.
Setup Personal Memory
-
Create ~/.claude directory:
mkdir -p ~/.claude -
Create personal CLAUDE.md:
touch ~/.claude/CLAUDE.md -
Add your preferences:
cat > ~/.claude/CLAUDE.md << 'EOF' # My Development Preferences ## About Me - Experience Level: [Your level] - Preferred Languages: [Your languages] - Communication Style: [Your style] ## Code Preferences - [Your preferences] EOF
Setup Directory-Specific Memory
-
Create memory for specific directories:
mkdir -p /path/to/directory/.claude touch /path/to/directory/CLAUDE.md -
Add directory-specific rules:
cat > /path/to/directory/CLAUDE.md << 'EOF' # [Directory Name] Standards This file overrides root CLAUDE.md for this directory. ## [Specific Standards] EOF -
Commit to version control:
git add /path/to/directory/CLAUDE.md git commit -m "Add [directory] memory configuration"
Verify Setup
-
Check memory locations:
# Project root memory ls -la ./CLAUDE.md # Personal memory ls -la ~/.claude/CLAUDE.md -
Claude Code will automatically load these files when starting a session
-
Test with Claude Code by starting a new session in your project
Official Documentation
For the most up-to-date information, refer to the official Claude Code documentation:
- Memory Documentation - Complete memory system reference
- Slash Commands Reference - All built-in commands including
/initand/memory - CLI Reference - Command-line interface documentation
Key Technical Details from Official Docs
Memory Loading:
- All memory files are automatically loaded when Claude Code launches
- Claude traverses upward from the current working directory to discover CLAUDE.md files
- Subtree files are discovered and loaded contextually when accessing those directories
Import Syntax:
- Use
@path/to/fileto include external content (e.g.,@~/.claude/my-project-instructions.md) - Supports both relative and absolute paths
- Recursive imports supported with a maximum depth of 5
- First-time external imports trigger an approval dialog
- Not evaluated inside markdown code spans or code blocks
- Automatically includes referenced content in Claude’s context
Memory Hierarchy Precedence:
- Managed Policy (highest precedence)
- Managed Drop-ins (
managed-settings.d/, v2.1.83+) - Project Memory
- Project Rules (
.claude/rules/) - User Memory
- User-Level Rules (
~/.claude/rules/) - Local Project Memory
- Auto Memory (lowest precedence)
Related Concepts Links
Integration Points
- MCP Protocol - Live data access alongside memory
- Slash Commands - Session-specific shortcuts
- Skills - Automated workflows with memory context
Related Claude Features
- Claude Web Memory - Automatic synthesis
- Official Memory Docs - Anthropic documentation